Mit Scraping Surgeon kannst du mit chirurgischer Präzision festlegen, welche Abschnitte einer Webseite ZimmWriter an die KI übermitteln soll. Dazu brauchst du ScrapeOwl und CSS-Kenntnisse (oder die Hilfe von jemandem, der sie hat).
Klingt interessant. Aber was soll das bringen?
Das lässt sich am besten mit einem Beispiel erklären. Stell dir eine Amazon-Produktseite für ein iPhone 15 Pro Max vor.
Die Produktseite enthält Informationen über das iPhone 15 Pro Max, aber auch über andere iPhone-Modelle, iPhone-Zubehör und vielleicht sogar andere Telefone. Sie könnte sogar Informationen über Produkte enthalten, die andere Leute zusammen mit dem iPhone gekauft haben.
Wenn ZimmWriter (oder jeder andere KI-Schreiber) die gesamte Seite ausliest und die gesamten ausgelesenen Daten zur Zusammenfassung an die KI schickt, ist das ein Problem. Das Problem ist ein zweifaches:
- Die KI könnte verwirrt werden, welche Informationen sich auf das iPhone 15 Pro Max beziehen
- Die KI könnte auch andere Informationen in die Zusammenfassung aufnehmen, die für das, wofür du die Zusammenfassung verwendest, nicht relevant sind (z. B. einen Produktbericht über das iPhone 15 Pro Max).
Scraping Surgeon ist ein Weg, um all diese überflüssigen Informationen herauszufiltern und nur relevante Informationen auslesen.
Das Fundament legen
Das Herzstück von Scraping Surgeon ist die Verwendung von Cascading Style Sheets (CSS) IDs und/oder Klassen, um zu identifizieren, welche Inhalte auf einer Webseite gescraped werden sollen.
Du hast vielleicht 0% Ahnung von CSS und das macht es sehr schwierig, neue Scraping Surgeon Domains ohne Hilfe einzurichten. Zumindest (und das erfordert null CSS-Kenntnisse) solltest du dein Amazon-Partner-Tag zum Standard-Amazon-Profil hinzufügen (im Dropdown-Menü Gespeicherte Domains) und dann auf die Schaltfläche Aktualisieren klicken. Danach solltest du dich nicht mehr mit Scraping Surgeon beschäftigen, es sei denn, jemand hilft dir.
Aber wenn du dich mutig fühlst und für das Abenteuer lebst, findest du hier eine Einführung in HTML und CSS. Um Scraping Surgeon zu benutzen, brauchst du ein paar Grundkenntnisse in beiden Bereichen.
HTML-Fibel
HTML ist das, was du siehst, wenn du in Chrome mit der rechten Maustaste auf den Hintergrund einer Webseite klickst und “Seitenquelle anzeigen” wählst.
Der obige Code wird HTML genannt und hat verschiedene „Tags”. Im obigen Beispiel:
- Apple iPhone 15 Pro Max, 1TB wird der „Inhalt” genannt
- ist der schließende Tag
Es gibt zwar viele HTML-Tags, aber einige der gängigsten sind:
- , , , , usw.
- Öffnende und schließende HTML-Tags für Überschriften
- Öffnende und schließende HTML-Absatz-Tags
- HTML div-Tags zum Öffnen und Schließen
- Ein div ist wie ein allgemeiner Container, der Dinge enthält
- HTML-Hyperlink-Tags zum Öffnen und Schließen
- HTML image öffnende und schließende Tags
- HTML span öffnende und schließende Tags
- Ein span ist wie ein div, aber für Inline-Inhalte (ohne Zeilenumbruch) gedacht.
Ein HTML-Tag ist wie das Innenleben eines Autos; es ist nicht schön, aber man braucht den Motor, die Stoßdämpfer und die Antriebswelle, sonst funktioniert das Auto nicht.
Die meisten Leute interessieren sich mehr für das Aussehen als für die Funktion des Autos. Dieses „Aussehen” wird durch CSS definiert.
CSS-Fibel
Cascading Style Sheets (CSS) sind wie die äußere Hülle eines Autos und verleihen einer Webseite ihr elegantes Aussehen.
Für die Gestaltung einer Seite werden so genannte CSS-Selektoren verwendet. Die beiden gängigsten sind ID- und Klassenselektoren. Am besten kann man sich ID- und Klassenselektoren als Schlüsselwörter vorstellen, die ein Webseitenentwickler definiert.
Sie fügen Ihren HTML-Tags einige CSS-Selektoren hinzu, und diese Selektoren (Schlüsselwörter) verweisen auf eine CSS-Datei, die jedes Schlüsselwort mit CSS-Code definiert. Klingt kompliziert, ist es aber nicht. Lassen Sie mich Ihnen ein sehr einfaches Beispiel geben.
Webseite HTML:
Hier sind einige Produktdetails zum neuen Apple iPhone!
CSS-Datei der Webseite:
#productTitle {
font-weight: 600;
font-size: 28px;
}
.center {
text-align: center;
}
.tagline {
font-weight: 400px;
font-size: 22px;
}
Ein CSS-ID-Selektor sollte nur einmal in der HTML-Datei vorkommen. In diesem Fall ist es productTitle und er ist der
Ein CSS-Klassenselektor kann mehrmals im HTML-Code vorkommen. Im obigen Beispiel ist er der Klasse
Tag zugewiesen. Du siehst, dass es als class=“center” im HTML, sondern als .center in der CSS-Datei.
Wenn du genau hinsiehst, siehst du auch, dass es möglich ist, einem einzigen HTML-Tag mehrere Klassen zuzuweisen. Im Absatz-Tag haben wir sowohl die Klasse center als auch die Klasse tagline zugewiesen, getrennt durch ein Leerzeichen.
Verschachtelte HTML-Tags
Das letzte wichtige Konzept, das du für Scraping Surgeon verstehen musst, ist das Konzept der verschachtelten HTML-Tags.
Here is some text
Here is some more text
Beachte, dass der übergeordnete div-Tag zwei untergeordnete Absatz-Tags enthält. Die Absatz-Tags befinden sich innerhalb des div-Tags (und sind daher untergeordnete Tags), weil sie nach dem öffnenden
Tag, aber vor dem schließenden
Tag.
Der Grund, warum dies für Scraping Surgeon wichtig ist, liegt darin, dass Scraping Surgeon bei einem Verweis auf ein übergeordnetes Tag alle Inhalte innerhalb des referenzierten Tags, einschließlich seiner Kinder, scrapen wird. Bitte erinnere dich an diesen Punkt, denn es ist wichtig, ihn zu verstehen.
Scraping Surgeon Konfiguration
Scraping Surgeon befindet sich im Menü ZimmWriter Optionen, da es sich um eine Funktion handelt, die man einfach einrichten kann. Wenn ZimmWriter eine Webseite scrapt, wird Scraping Surgeon verwendet, wenn die in Scraping Surgeon gespeicherte “Domain” (mit aktiviertem Kontrollkästchen) mit der Domain der gescrapten Webseite übereinstimmt.
Domain
Für eine Domain gelten die folgenden Regeln:
- Sie muss einen Punkt enthalten
- amazon.de = OK
- amazon. = OK (nützlich für den Abgleich mehrerer TLDs)
- Er darf nicht www enthalten
- Er darf kein https enthalten
CSS-Titelklasse/ID oder HTML-Tags h1 oder h2
Du kannst entweder eine einzelne CSS-Klasse (.class) oder ID (#id) angeben, die das Element (oder übergeordnete Element) repräsentiert, das den Titel der Seite enthält, oder stattdessen einen der HTML-Tags h1 oder h2 angeben.
Im folgenden Amazon-Beispiel habe ich mich entschieden, den HTML-Tag h1 nicht anzugeben, weil Amazon-Seiten manchmal mehrere h1-Tags haben und das die KI durcheinander bringen würde.
Deshalb habe ich mich für die CSS-ID #productTitle entschieden, die normalerweise immer mit einem Amazon-Produkttitel erscheint. Ein Beispiel für den HTML-Code lautet wie folgt:
Beachten Sie, dass der Titelinhalt „Apple iPhone 15 Pro Max, 1TB” von einem HTML span-Tag mit einer id=„productTitle” umgeben ist. Ich habe mir verschiedene Amazon-Produktseiten angesehen, und sie alle scheinen diese ID zur Bezeichnung des Produkttitels zu verwenden.
Was wäre, wenn ich die Klasse „.product-title-word-break” anstelle der gefundenen ID verwendet hätte? Nun, die Klasse „.product-title-word-break” wird viele Male auf einer Amazon-Produktseite wiederholt. Sie ist also eine schlechte Wahl, da sie viele andere Dinge als nur den Produkttitel enthalten wird.
Der Trick besteht also darin, CSS-Klassen und IDs zu finden, die sich in der Regel nur auf den Artikel beziehen, den Sie auslesen möchten, und die auf vielen ähnlichen Webseiten derselben Domain konsistent sind (z. B. verwenden alle Amazon-Seiten dieselben Bezeichner für die Elemente).
CSS Image Class/ID
Die Bildklasse (.class) oder ID (#id) ist optional. Wenn Sie sich entscheiden, sie zu verwenden, dann gilt sie in diesen Situationen:
- In Penny Arcade aktiviert eine Scraping Surgeon-Domain-Übereinstimmung SS. Wenn der Bild-CSS-Selektor vorhanden ist und ein gültiges Bild gefunden wird (jpg, jpeg, png oder webp), dann wird das Bild heruntergeladen und auf Ihrer Festplatte unter demselben Namen wie der Dateiname des Blogposts gespeichert. Es wird auch in WordPress als Featured Image hochgeladen, wenn Sie Ihre Website verlinken. Hinweis: Es liegt in Ihrer Verantwortung, alle Urheberrechtsgesetze zu beachten und zu befolgen.
- Wenn Sie in SEO Writer eine Scraping Surgeon-Domain-Übereinstimmung für eine Untertitel-URL angeben, wird SS aktiviert. Wenn der Bild-CSS-Selektor vorhanden ist und ein gültiges Bild gefunden wird (jpg, jpeg, png oder webp), wird das Bild heruntergeladen und auf Ihrer Festplatte mit demselben Namen wie der Dateiname, aber mit 0001, 0002, 0003 usw. am Ende, gespeichert.
- Die numerische Reihenfolge wird verwendet, wenn Sie mehrere Unterrubriken mit jeweils eigenen Bildern haben. Es wird auch als Bild für die Zwischenüberschrift in WordPress hochgeladen (nicht als Featured Image), wenn Sie Ihre Website verlinken. Hinweis: Es liegt in Ihrer Verantwortung, alle Urheberrechtsgesetze zu beachten und zu befolgen.
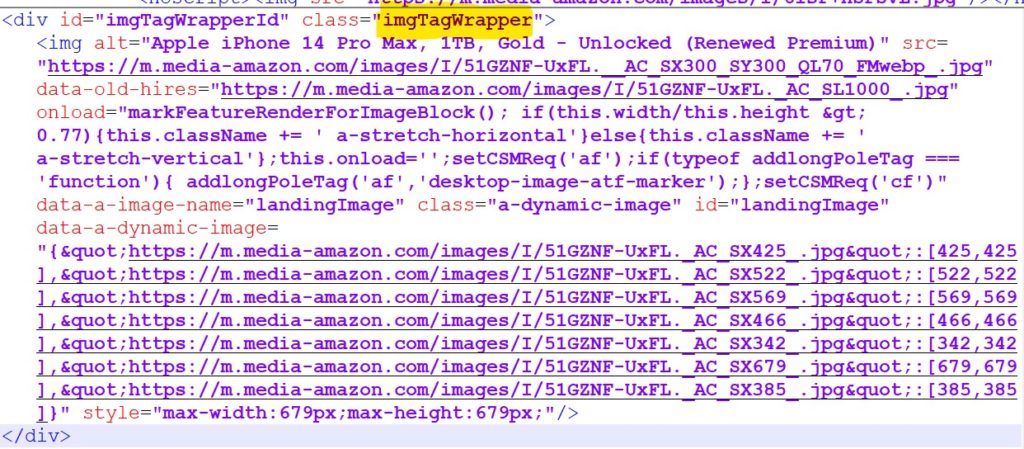
Der Selektor, den ich für das Bild gewählt habe, war #imgTagWrapper. Der Tag ist ein übergeordneter Tag, weil er den Tag mit dem gewünschten Bild enthält.
CSS Text Classes/IDs or HTML Tags p, h2, ul, ol, li, section, span
In ZimmWriter kannst du bis zu fünf CSS-Klassen und/oder IDs und/oder HTML-Tags p, h2, ul, ol, li, section, span angeben, die für verschiedene Abschnitte auf der Seite stehen, deren Text ausgelesen werden soll.
Trenne die CSS-Elemente und HTML-Tags durch ein Komma.
Hier ist die Liste, die ZimmWriter (zum Zeitpunkt der Erstellung dieses Artikels) für Amazon verwendet:
#feature-bullets, #productDescription_feature_div, #prodDetails, #tech, .review-text
Du kannst die CSS-Selektoren frei mit den erlaubten HTML-Tags kombinieren. Hier ist ein Beispiel:
#feature-bullets, p, #prodDetails, ol, .review-text
String zum Anhängen an das Ende der URL / Amazon Affiliate Code
Für eine Amazon-Domain fügst du einfach deinen Affiliate-Code hinzu. Er sollte aus einer Zeichenfolge, einem Bindestrich und einigen Zahlen bestehen (z. B. abc034-20).
Bei allen anderen Domains kannst du an das Ende der URL anhängen, was du willst.
Wie funktioniert das bei der Ausführung von ZimmWriter?
Diese Zeichenfolge bzw. dieser Partnercode wird für den Aufruf zur Aktion in ZimmWriter verwendet. Im Moment erstellt ZimmWriter einen Call-to-Action-Button in zwei Instanzen:
- In Penny Arcade kannst du beim Scraping einer Domain, die mit einer von Scraping Surgeon gespeicherten Domain übereinstimmt, eine benutzerdefinierte Gliederungsvariable {cta} in einer benutzerdefinierten Gliederung verwenden. ZimmWriter erstellt dann am Ende dieses Unterüberschriftenabschnitts eine Schaltfläche, die auf die gescrapte URL verweist und am Ende den angehängten String oder den Amazon-Partnercode enthält.
- Wenn du im SEO Writer eine Domain für eine Unterüberschrift scrapst, die mit einer von Scraping Surgeon gespeicherten Domain übereinstimmt, und das Kontrollkästchen “Produktlayout auslösen” aktiviert ist. ZimmWriter erstellt eine Schaltfläche am Ende der Unterüberschrift, die auf die gescrapte URL verlinkt und den angehängten String oder Amazon-Partnercode am Ende enthält.
Als Rezension behandeln
Im Moment gilt diese Einstellung nur für Penny Arcade, wenn du nicht den Originaltitel verwendest. Sie führt dazu, dass die KI den Titel mit dem Wort “Rezension” schreibt, das irgendwo darin vorkommt.
Nehmen wir an, du durchsuchst eine Amazon-Seite für ein “iPhone 15 Pro Max”.
Ohne die Option “als Rezension behandeln” zu aktivieren, könnte ZimmWriter einen Penny Arcade Artikel mit dem Titel “iPhone 15 Pro Max: Unglaubliche Funktionen und solide Leistung” erstellen.
Wenn “als Rezension behandeln” aktiviert ist, könnte ZimmWriter einen Penny Arcade-Artikel mit dem Titel “iPhone 15 Pro Review” erstellen: Unglaubliche Funktionen und solide Leistung.
Aktiviere
Aktiviere die Domain für die Erkennung durch Scraping Surgeon oder entferne das Häkchen, um sie zu deaktivieren. Du kannst die Domain auch aus Scraping Surgeon löschen, aber in manchen Situationen ist es sinnvoller, das Häkchen bei “Aktivieren” zu entfernen.
Gespeicherte Domains
Du kannst bis zu 50 Domains in Scraping Surgeon speichern. Auch hier gilt: Einstellen und vergessen. Du musst eine Domain nicht “laden”. Solange die Domain mit aktiviertem Kontrollkästchen gespeichert wird, ist sie für die Erkennung beim Scraping in ZimmWriter gültig.
Speichern / Aktualisieren / Löschen
Klicke auf die Schaltfläche Speichern, um eine neue Domain für Scraping Surgeon zu speichern.
Drücke den Aktualisieren-Button, um Änderungen an einer bestehenden Domain zu speichern.
Drücke auf die Schaltfläche “Löschen”, um die Domäne zu löschen.



