Das Scraping der Google-Suchmaschinenergebnisseite (“SERP”) ist die Lösung, um das Gehirn der KI automatisch mit relevantem und detailliertem Wissen über ein Thema zu füttern.
Reden wir einen Moment auf hohem Niveau.
Die KI hat einen Cutoff aus der Perspektive des Wissens. Die Grenze für GPT 3.5 ist 2021 und die Grenze für GPT 4 ist 2023. Aber selbst wenn die KI über Wissen zu einem Thema verfügt, bedeutet das nicht, dass sie über tiefes Wissen zu diesem Thema verfügt.
Wenn du also einen Artikel über ein Thema schreiben willst, über das die KI nichts weiß, oder über ein Thema, das tiefes Wissen erfordert, solltest du die SERP-Scraping-Funktion von ZimmWriter nutzen.
Hinter den Kulissen (High Level)
Ich denke, es ist wichtig, mit dir zu teilen, was bei einem SERP-Scrape hinter den Kulissen vor sich geht. Lass uns das mal aus der Perspektive des Bulk Writers in ZimmWriter besprechen:
- Gib den Titel eines Blogbeitrags in den Bulk Writer in ZimmWriter ein
- Aktiviere SERP-Scraping (erfordert ScrapeOwl)
- Konfiguriere alle Optionen und starte dann den Bulk Writer
- ZimmWriter führt dann die folgenden Schritte aus:
- Kontaktiere ScrapeOwl, um eine Google-Suche nach dem Titel des Artikels durchzuführen.
- Du erhältst von ScrapeOwl eine Liste der Webseiten, die für diesen Begriff rangieren, zusammen mit Fragen von Leuten, die ebenfalls Fragen stellen, und einigen anderen Daten.
- Speichere den SERP-Scrape in der Cache-Datenbank. Bis zu 5.000 SERP-Scrapes können gleichzeitig im Cache gespeichert werden.
- Bestimme, welche Webseiten, die für den Begriff ranken, für diesen Begriff relevant sind.
- Bei sehr eng gefassten Suchanfragen gibt es manchmal keine Ergebnisse, die das Thema behandeln (z. B. wenn du versuchst zu googeln “wie man einer Schnecke das Fahrradfahren beibringt”, wirst du sehen, dass es nichts dazu gibt).
- Wenn keine Ergebnisse gefunden werden, bricht ZimmWriter den Vorgang ab.
- Scrape bis zu 5 Webseiten, die für die Suchanfrage als relevant eingestuft wurden, aus der SERP
- Wenn es sich bei mehreren Ergebnissen um YouTube-Videos handelt, wird nur das erste YouTube-Videotranskript ausgewertet.
- Jede Website wird gescraped, die Zwischenüberschriften werden gesammelt, SEO-Keywords werden extrahiert und eine Zusammenfassung mit Hilfe von KI wird für jede Website erstellt.
- Jede gescrapte Webseite wird in der Cache-Datenbank gespeichert. Im Cache können bis zu 5.000 Webseiten gleichzeitig vorhanden sein.
- Verwende die Zwischenüberschriften der bis zu 5 Webseiten, um deine Gliederung zu erstellen.
- Verwende die Zusammenfassungen der bis zu 5 Webseiten, um Diskussionspunkte für jede Unterüberschrift in deinem Artikel zu erstellen (z.B. jede H2, H3, etc.).
- Verwende die SEO-Keywords, die du aus den gescrapten Webseiten ermittelt hast, um sie in deinen Artikel einzufügen.
Wir hoffen, dass dieser Überblick nicht nur etwas Licht ins Dunkel bringt, sondern auch erklärt, warum es länger dauert, einen Artikel mit SERP-Scraping zu schreiben als ohne.
Geolocation-Zeug
Die Standardeinstellung für die Geolokalisierung ist Vereinigte Staaten (die google.com verwendet) und der Standardstandort ist Houston, TX, Vereinigte Staaten. Wenn du nur google.com scrapen willst und dir die Geolokalisierung egal ist, dann lass einfach alles stehen und liegen und es wird wunderbar funktionieren.
WICHTIGER HINWEIS: Die Zwischenspeicherung funktioniert nur auf der Grundlage des eingegebenen Titels und berücksichtigt nicht den geografischen Standort. Wenn du also einen Titel in den USA scrapen lässt und dann fragst, ob du ihn in Kanada erneut scrapen sollst, wird der gecachte Scrape aus den USA verwendet. Um dies zu vermeiden, musst du das Kontrollkästchen Cache überschreiben aktivieren.
SERP-Scraping im Bulk Writer
Wie SERP-Scraping im Bulk Writer funktioniert, habe ich oben schon beschrieben, aber es gibt noch ein paar weitere wichtige Punkte.
Das SERP-Scraping-Menü hat mehrere Optionen:
- SERP-Cache für übereinstimmende Titel überschreiben – aktiviere dieses Kästchen, um einen vorhandenen alten Cache für einen übereinstimmenden Blogpost-Titel zu überschreiben, anstatt ihn zu verwenden.
- Webseiten-Cache für übereinstimmende URLs überschreiben – aktiviere dieses Kontrollkästchen, um einen vorhandenen alten Cache für eine übereinstimmende URL zu überschreiben, die beim SERP-Scrape gefunden werden könnte.
- SEO-Schlüsselwörter aus SERP deaktivieren – aktiviere dieses Kontrollkästchen, damit ZimmWriter keine SEO-Schlüsselwörter aus den SERP verwendet und du das Kontrollkästchen “Automatische Schlüsselwörter” aktivieren kannst, um AI-generierte Schlüsselwörter zu aktivieren, wenn du das möchtest.
- PAA für FAQ deaktivieren – aktiviere dieses Kontrollkästchen, damit ZimmWriter nicht die von Google gestellten Fragen als FAQ-Fragen verwendet und stattdessen KI-generierte Fragen einsetzt.
Hier sind noch ein paar Dinge, die du im Bulk Writer beachten solltest:
- SERP Scraping ist mit der SEO CSV kompatibel. Es gilt der gesunde Menschenverstand. Wenn einer CSV-Zeile eine Gliederung, SEO-Keywords oder Hintergrundinformationen fehlen, werden die SERP-Daten für diese Teile verwendet.
- SERP-Scraping ist auch mit der Funktion für benutzerdefinierte Gliederungen kompatibel, aber das hängt von deiner Erfahrung ab.
SERP Scraping im SEO Writer
Die Schaltfläche SERP Scraping befindet sich in Schritt 2 des SEO Writer-Menüs.
Ein Wort zum *Wenn* in Bezug auf Zusammenfassungen aus der SERP
Eine Sache, die ich zuerst erklären muss und die ich mit größter Wichtigkeit betone, ist, *wann* die Zusammenfassungen von den bis zu 5 gescrapten Websites im SEO Writer verwendet werden. Die Zusammenfassungen sind für dich im Frontend nicht sichtbar, werden aber im Backend beim Schreiben des Artikels verwendet.
Im Bulk Writer werden die Zusammenfassungen verwendet, um Diskussionspunkte für jede Zwischenüberschrift zu erstellen.
Aber im SEO Writer werden die Zusammenfassungen verwendet, um Diskussionspunkte für jede Unterüberschrift zu generieren die keine “URL für Scraping” und keine “Hintergrundinformationen” für diese spezifische Unterüberschrift enthält.
Lies das noch ein paar Mal.
Ich erkläre es dir jetzt noch einmal, aber in umgekehrter Reihenfolge. Wenn du im Feld “URL für Scraping” eine URL für eine Unterüberschrift oder Hintergrundinformationen für eine Unterüberschrift angibst, dann werden die Zusammenfassungen der Webseiten aus dem SERP-Scrape nicht für diese spezielle Unterüberschrift verwendet werden.
Ein Wort zum globalen Hintergrund
Du kannst den SEO Writer immer noch zu 100% so verwenden, wie du ihn vor dem SERP-Scraping verwendet hast. Aber die Art und Weise, wie du den globalen Hintergrund verwendest, sollte sich ändern, wenn du SERP-Scraping betreibst.
Die KI braucht Fleisch, um über Nischenthemen zu schreiben und in diese Themen einzutauchen. Ohne SERP-Scraping würdest du dieses Fleisch im globalen Hintergrund (bis zu 1.200 Wörter) oder im Hintergrund einer bestimmten Unterüberschrift (bis zu 500 Wörter) bereitstellen.
Beim SERP-Scraping brauchst du jedoch keinen langen globalen Hintergrund mehr. Tatsächlich ist er sogar schädlich und eine Geldverschwendung. Die Faustregel für SERP-Scraping lautet…
- Verwende einen kurzen globalen Hintergrund von 75 Wörtern, wenn du die KI über ein enges oder Nischenthema schreiben lässt.
- Verwende keinen globalen Hintergrund, wenn du die KI über ein breites Thema schreiben lässt.
Warum?
Erinnerst du dich daran, wie ich (ein paar Absätze weiter oben) die “Diskussionspunkte” erwähnt habe, die für jede Unterüberschrift mithilfe der aus den SERP generierten Zusammenfassungen erstellt werden?
Da diese Diskussionspunkte für jede Unterrubrik spezifisch sind (d.h. für jede Unterrubrik werden neue Diskussionspunkte generiert), sind sie viel nützlicher als ein monströser, 1.200 Wörter umfassender Hintergrund, der nur bruchstückhaft auf eine Unterrubrik zutrifft.
Außerdem haben die Diskussionspunkte den zusätzlichen Vorteil, dass sie Wiederholungen vermeiden. Eine häufige Beschwerde bei der Verwendung eines langen globalen Hintergrunds für einen Artikel mit mehr als 10 Unterüberschriften ist die Wiederholung von Inhalten in verschiedenen Unterüberschriften. Bei der Verwendung der SERP-Scraping-Funktion ist dies jedoch in der Regel nicht der Fall.
TLDR: Wenn du das SERP-Scraping im SEO Writer verwendest, solltest du keinen langen globalen Hintergrund verwenden; etwa 75 Wörter sind ausreichend.
Vorab-Scraping der SERP mit der Schaltfläche “SERP jetzt scrapen”
Wenn du auf die Schaltfläche zum Scrapen der SERP drückst, siehst du die Schaltfläche “Scrape the SERP Now” (die im Menü des Bulk Writers nicht vorhanden ist).
Wenn du auf diese Schaltfläche drückst, wird als erstes ein SERP-Scrape des Blogpost-Titels gestartet.
Wenn du diesen Button drückst, werden die Menüs geschlossen und ZimmWriter durchsucht die SERP nach dem Titel deines Blogbeitrags. Sobald dies abgeschlossen ist, fügt ZimmWriter Folgendes hinzu:
- einen globalen Hintergrund
- eine Liste der H2 und H3 Unterüberschriften der Mitbewerber aus der SERP
- eine Liste von SEO-Keywords
Wenn du die SERP im Voraus scrapst (wie du es gerade getan hast), kannst du jetzt “Option 3” verwenden, um deine Zwischenüberschriften auf der Grundlage des globalen Hintergrunds der SERP + der Zwischenüberschriften der Konkurrenz zu generieren.
Wenn du bereit bist, den Artikel von ZimmWriter schreiben zu lassen, kannst du auf eine der beiden Schaltflächen unten im SEO Writer-Menü klicken (z. B. SEO Writer starten (mit Scraping-URLs)” oder “SEO Writer starten (ohne Scraping-URLs)”) und ZimmWriter wird die gescrapten SERP-Daten zum Schreiben des Artikels verwenden.
Scraping der SERP ohne Pre-Scrape
Die Verwendung der Schaltfläche “Scrape the SERP Now” ist optional. Du kannst stattdessen das SERP-Scraping aktivieren, deine Gliederung erstellen, alle Details ausfüllen, alle Optionen konfigurieren und dann entweder die Schaltflächen “SEO Writer starten (mit Scraping-URLs)” oder “SEO Writer starten (ohne Scraping-URLs)” drücken.
Was wird passieren?
ZimmWriter scrabbelt zuerst die SERP (sofern sie nicht schon vorher gescrabbt wurde, wie oben beschrieben) und schreibt dann deinen Artikel.
Häufig gestellte Fragen
Wie lange dauert das SERP-Scraping?
Stelle zu 100 % sicher, dass dein OpenAI-Konto auf Nutzungsstufe 2 ist. Andernfalls wirst du feststellen, dass das SERP-Scraping SEHR langsam ist. Du findest dein Ratenlimit oben links in der dieser Seite.
Du kannst die Nutzungsstufe 2 ganz einfach erreichen, indem du 50 Dollar auf dein OpenAI-Konto auflädst. Mehr über die Nutzungsstufen und Tarifgrenzen erfährst du auf der OpenAI Tarifgrenze Seite.
Im Allgemeinen kann das Scrapen der SERP (bevor ZimmWriter mit dem Schreiben deines Artikels beginnt) zwischen 5 und 20 Minuten dauern, vorausgesetzt, du bist auf Nutzungsebene 2. Sobald der SERP-Scrape und die Webseiten-Scrapes im Cache gespeichert sind, wird diese Zeit auf Null reduziert.
Warum bleiben einige Websites, die gescraped werden, für gefühlte 5–10 Minuten bei 0% Fortschritt?
Wenn ZimmWriter auf eine “neue” Domain für eine Webseite stößt, geht er davon aus, dass er keine ausgefallenen ScrapeOwl-Einstellungen (wie Premium-Proxys, Javascript usw.) benötigt. ZimmWriter versucht dann, die Webseite mit den Standardeinstellungen zu scrapen und erhält 1 Credit für einen erfolgreichen Scrape.
Aber manchmal lässt sich die Webseite nicht scrapen, weil die Domain den Scraper blockiert oder weil sie JavaScript verwendet, um den Inhalt zu rendern, usw.
ZimmWriter geht also wie folgt vor:
- Er versucht 3x, die Webseite zu scrapen.
- Wenn alle 3x fehlschlagen, versucht ZimmWriter es noch 3x, aber mit aktivierten “Premium Proxies.
- Wenn alle 3x fehlschlagen, versucht ZimmWriter 3x weitere Versuche, aber mit aktiviertem “render_js.
- Wenn alle 3x fehlschlagen, versucht ZimmWriter 3x weitere Versuche, aber mit “block_resources” auf false gesetzt
Hinweis: Jeder Versuch kann bis zu 60 Sekunden dauern, bevor eine Zeitüberschreitung eintritt, und fehlgeschlagene Versuche kosten keine ScrapeOwl-Credits!
Wenn ZimmWriter die Webseite zu irgendeinem Zeitpunkt erfolgreich scrapen konnte und Premium Proxies, render_js oder block_resources erforderlich waren, speichert ZimmWriter die Domain mit dieser Konfiguration in den ScrapeOwl-Einstellungen.
Wenn das Scrapen nicht erfolgreich war, fügt ZimmWriter die Domain trotzdem zum ScrapeOwl-Einstellungsmenü hinzu, allerdings mit dem Status “blockiert”, was bedeutet, dass die Domain übersprungen wird, wenn sie in Zukunft bei einem SERP-Scrape gefunden wird.
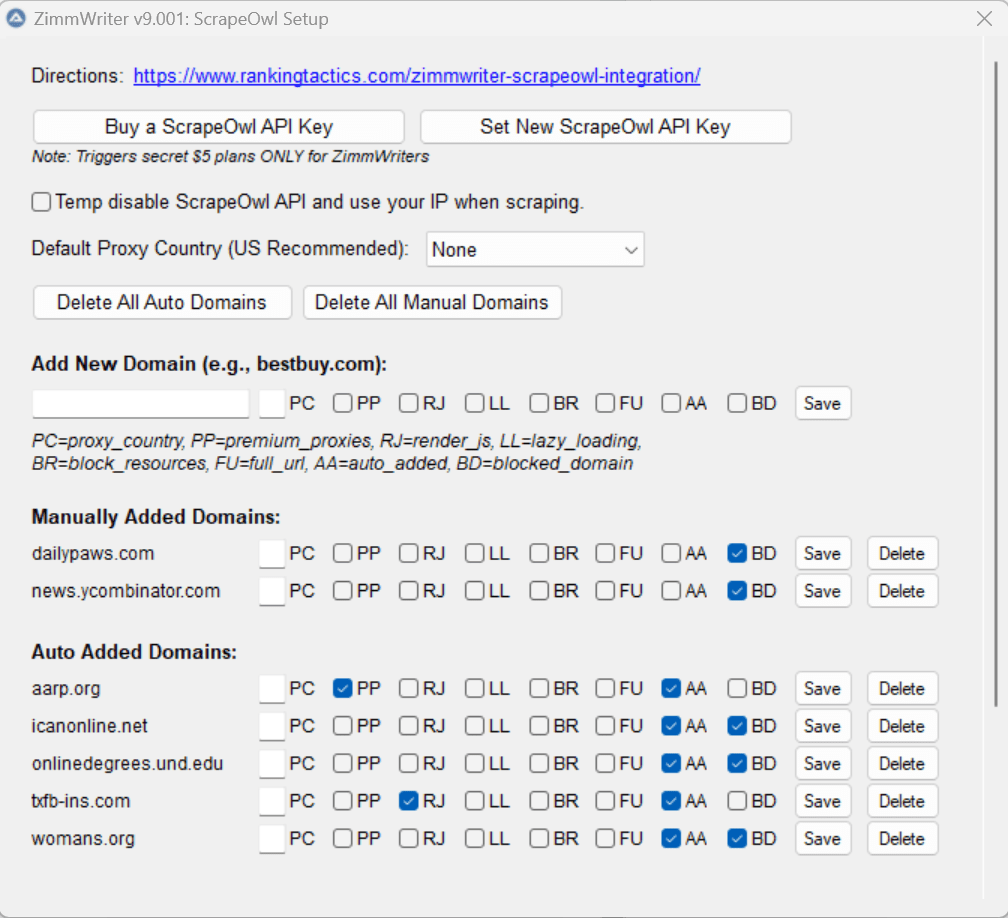
Siehst du den Bereich “automatisch hinzugefügte Domains”? Das sind alles Domains, die ZimmWriter beim Scrapen gefunden hat, mit denen er zu kämpfen hatte und die dann mit einer bestimmten Einstellung zur Datenbank hinzugefügt wurden.
Im Moment kann ZimmWriter bis zu 50 automatisch hinzugefügte Domains speichern. Sobald das Limit erreicht ist, werden die ältesten hinzugefügten Domains entfernt, um Platz für die neueren zu schaffen. Wer zuerst kommt, mahlt zuerst.
Wenn du beim SERP-Scraping häufig auf eine Domäne stößt, kannst du das Häkchen bei “AA” entfernen, auf “Speichern” klicken und diese Domäne wird dann dem “manuell hinzugefügten Bereich” hinzugefügt. Das gleiche Limit von 50, aber diese Domains werden nicht automatisch entfernt.



